hadoop1.x和hadoop2.x的区别:
Hadoop1.x版本:
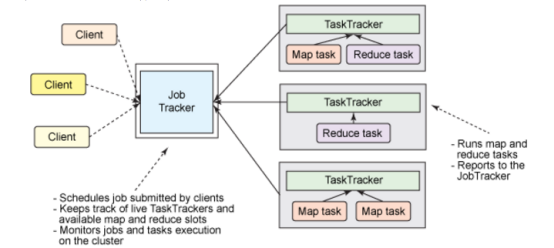
内核主要由Hdfs和Mapreduce两个系统组成,其中Mapreduce是一个离线分布式计算框架,由一个JobTracker和多个TaskTracker组成。
JobTracker的主要作用:JobTracker是框架的中心,接收任务,计算资源,分配资源,分配任务,与DataNode进行交流等功能。决策程序失败时 重启等操作。又当爹又当妈。
TaskTracker同时监视当前机器上的task运行状况。TaskTracker需要把这些信息通过心跳,发送给jobTracker,jobTracker会收集这些信息以给新提交的job分配运行在那些机器上。
存在问题:
1.JobTracker是mapreduce的集中处理点,存在单点故障;
2.JobTracker完成了太多任务,造成了过多资源的消耗,当mapreduce job非常多的时候,会造成很大的内存消耗,同时 也增加了JobTracker失效的风险,这也是业界普遍总结出老的hadoop的mapreduce只能支持4000节点主机的上限。
Hadoop2.x版本:
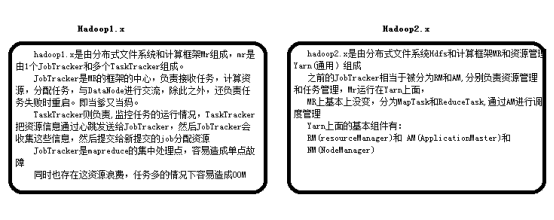
第二代的hadoop版本,为克服hadoop1.0中的hdfs和mapreduce存在的各种问题而提出的。针对hadoop1.x中的单NameNode制约HDFS的扩展性问题,提出了HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展,同时它彻底解决了NameNode单点故障问题,针对Hadoop1.0中的Mapreduce的Mapreduce在扩展性和多框架支持等方面不足。
MRv2具有与MRv1相同的编程模型和数据处理引擎,唯一不同的是运行时环境。MRv2是在MRv1基础上经加工之后,运行于资源管理框架YARN之上的计算框架MapReduce。它的运行时环境不再由JobTracker和TaskTracker等服务组成,而是变为通用资源管理系统YARN和作业控制进程ApplicationMaster,其中,YARN负责资源管理和调度,而ApplicationMaster仅负责一个作业的管理。简言之,MRv1仅是一个独立的离线计算框架,而MRv2则是运行于YARN之上的MapReduce。
整体上:分为两个方面
1.任务调度和资源管理方面:
1)Hadoop1中的JobTracker是一个功能集中的部分,负责资源的分配和任务的分配,所以JobTracker单点出问题就会造成整个集群无法使用了,而且MapReduce模式是集成在Hadoop1中,不易分解,不好添加其他模式;
2)Hadoop2中,ResourceManager(RM)就是负责资源的分配,NodeManager(NM)是从节点上管理资源的,而ApplicationMaster(AM)就是一个负责任务分配的组件,根据不同的模式有不同的AM,因此MapReduce模式有自己独有的AM;
2.关于文件系统:
文件系统HDFS,1.x版本没有HA功能,只能有一个NameNode;而2.x添加了HA部分,还可以有多个NameNode同时运行,每个负责集群中的一部分。
Mapreduce流程包括shuffle阶段
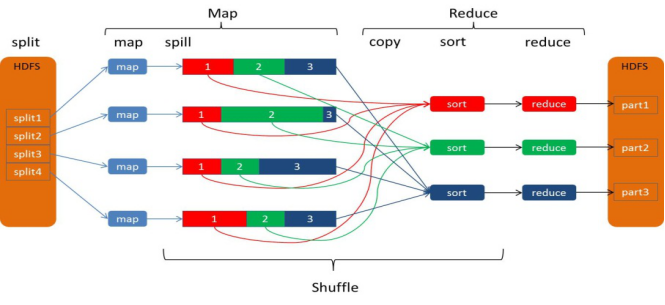
Mapreduce的过程整体上分为四个阶段:InputFormat MapTask ReduceTask OutPutFormat 当然中间还有shuffle阶段
InputFormat:
我们通过在runner类中用 job.setInputPaths 或者是addInputPath添加输入文件或者是目录(这两者是有区别的)不同的业务他们的输入是不同的,我所完成的项目中使用了一个TableMapReduceUtil(hbase和Mapreduce的整合类)来设置的输入目录。
默认是FileInputFormat中的TextInputFormat类,获取输入分片,使用默认的RecordReader:LineRecordReader将一个输入分片中的每一行按\n分割成key-value key是偏移量 value是每一行的内容。调用一次map()方法。一个输入分片对应一个Maptask任务,
MapTask:
每一个key-value经过map()方法业务处理之后开始开始shuffle阶段
以WordCount为例:该阶段只做+1的操作,(aaa,1),然后开向缓冲区写入数据
Shuffle:
Map-Shuffle:
写入之前先进行分区Partition,用户可以自定义分区(就是继承Partitioner类),然后定制到job上,如果没有进行分区,框架会使用 默认的分区(HashPartitioner)对key去hash值之后,然后在对reduceTaskNum进行取模(目的是为了平衡reduce的处理能力),然后决定由那个reduceTask来处理。
将分完区的结果<key,value,partition>开始序列化成字节数组,开始写入缓冲区。
随着map端的结果不端的输入缓冲区,缓冲区里的数据越来越多,缓冲区的默认大小是100M,当缓冲区大小达到阀值时 默认是0.8【spill.percent】(也就是80M),开始启动溢写线程,锁定这80M的内存执行溢写过程,内存—>磁盘,此时map输出的结果继续由另一个线程往剩余的20M里写,两个线程相互独立,彼此互不干扰。
溢写spill线程启动后,开始对key进行排序(Sort)默认的是自然排序,也是对序列化的字节数组进行排序(先对分区号排序,然后在对key进行排序)。
如果客户端自定义了Combiner之后(相当于map阶段的reduce),将相同的key的value相加,这样的好处就是减少溢写到磁盘的数据量(Combiner使用一定得慎重,适用于输入key/value和输出key/value类型完全一致,而且不影响最终的结果)
每次溢写都会在磁盘上生成一个一个的小文件,因为最终的结果文件只有一个,所以需要将这些溢写文件归并到一起,这个过程叫做Merge,最终结果就是一个group({“aaa”,[5,8,3]})
集合里面的值是从不同的溢写文件中读取来的。这时候Map-Shuffle就算是完成了。
一个MapTask端生成一个结果文件。
ReduceTask:
Reduce-Shuffle:
接下来开始进行Reduce-Shuffle 阶段。当MapTask完成任务数超过总数的5%后,开始调度执行ReduceTask任务,然后ReduceTask默认启动5个copy线程到完成的MapTask任务节点上分别copy一份属于自己的数据(使用Http的方式)。
这些拷贝的数据会首先保存到内存缓冲区中,当达到一定的阀值的时候,开始启动内存到磁盘的Merge,也就是溢写过程,一致运行直到map端没有数据生成,最后启动磁盘到磁盘的Merge方式生成最终的那个文件。在溢写过程中,然后锁定80M的数据,然后在延续Sort过程,然后记性group(分组)将相同的key放到一个集合中,然后在进行Merge
然后就开始reduceTask就会将这个文件交给reduced()方法进行处理,执行相应的业务逻辑
OutputFormat:
默认输出到HDFS上,文件名称是part-00001
当我们输出需要指定到不同于HDFS时,需要自定义输出类继承OutputFormat类
Mapreduce编程模型
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {}
}
public static class MyReduce extends Reducer<Text, IntWritable, Text, Text> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {}
}
public class Runner extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Runner(), args);
}
}
Mapreduce中的技术:
Job依赖:
应用背景:当某个需求使用一个Mapreduce程序无法完成业务计算时,通常需要两个mapreduce来配个完成 其实就是两个job
关键代码:

自定义数据类型:二次排序
Class MyWritable Implements WritableComparable<MyWritable>
重写 write() readFile() compareTo() HashCode() equals()方法
自定义合并:
继承Reducer 重写reduce()方法
自定义分区:
继承 Partitioner重写getPartition()方法
自定义分组:比较字段是String类型

如果是Int类型就使用以下这种方法

添加缓冲文件:

自定义多文件输出:
查看MutipleFileOutput.java